Node Auto Provisioning (NAP) significantly evolves how Azure Kubernetes Service manages infrastructure resources. This feature fundamentally transforms the traditional approach to node pool management by dynamically provisioning infrastructure based on workload requirements rather than predefined configurations. This is a game changer in AKS because when you provision an AKS instance, you get node pools that use Virtual Machine Scale Sets. You're locked into those SKUs unless you start juggling around creating node pools, cordoning and draining the other ones to get a new SKU in place.
With this new method of managing nodes in AKS, you can quickly start combining spot instances and regular instances and have a performance boost while gaining cost management capabilities by implementing spot instances in the mix.
The Technical Architecture Behind NAP
Node Auto Provisioning is built on Karpenter, an open-source node provisioning project initially contributed to the Cloud Native Computing Foundation (CNCF) by Amazon. Microsoft has implemented this technology for AKS and made the AKS provider open source as well. Unlike the traditional Cluster Autoscaler, which works with predefined node pools, NAP dynamically analyzes pending pod resource requirements and provides the optimal VM configurations to meet those needs.
The architecture consists of several components working in concert. When pods are scheduled but remain pending due to insufficient resources, NAP intercepts these events and analyzes the resource requirements. It then interfaces directly with Azure's Compute API to rapidly provision the most appropriate VM size based on the pending workloads' specific CPU, memory, and other resource requirements. This integration with Azure's infrastructure APIs enables NAP to make precise scaling decisions with significantly reduced latency compared to traditional scaling mechanisms.
NAP uses custom resource definitions (CRDs) from Karpenter that are automatically installed when you enable the feature. After enabling NAP, these CRDs define the automation logic and constraints for node provisioning decisions.
How NAP Evaluates Workload Requirements
NAP's process for determining the optimal node configuration involves sophisticated analysis of pod specifications. It examines resource requests and limits, taints and tolerations, node affinity rules, and other scheduling constraints. Based on this analysis, NAP selects from hundreds of available VM types to find the most cost-effective option that satisfies all requirements.
For example, if a pending pod requests 4 CPU cores and 16GB of memory with GPU acceleration, NAP will automatically provision a node with appropriate GPU capabilities rather than manually forcing you to create a specialized node pool in advance. This dynamic matching of infrastructure to workload needs makes NAP powerful for diverse or changing application requirements.
Implementation and Configuration
Prerequisites and Setup
Setting up NAP requires several prerequisites that must be completed before deployment:
An Azure subscription with appropriate permissions
Azure CLI with the aks-preview extension
az extension add --name aks-preview
az extension update --name aks-preview
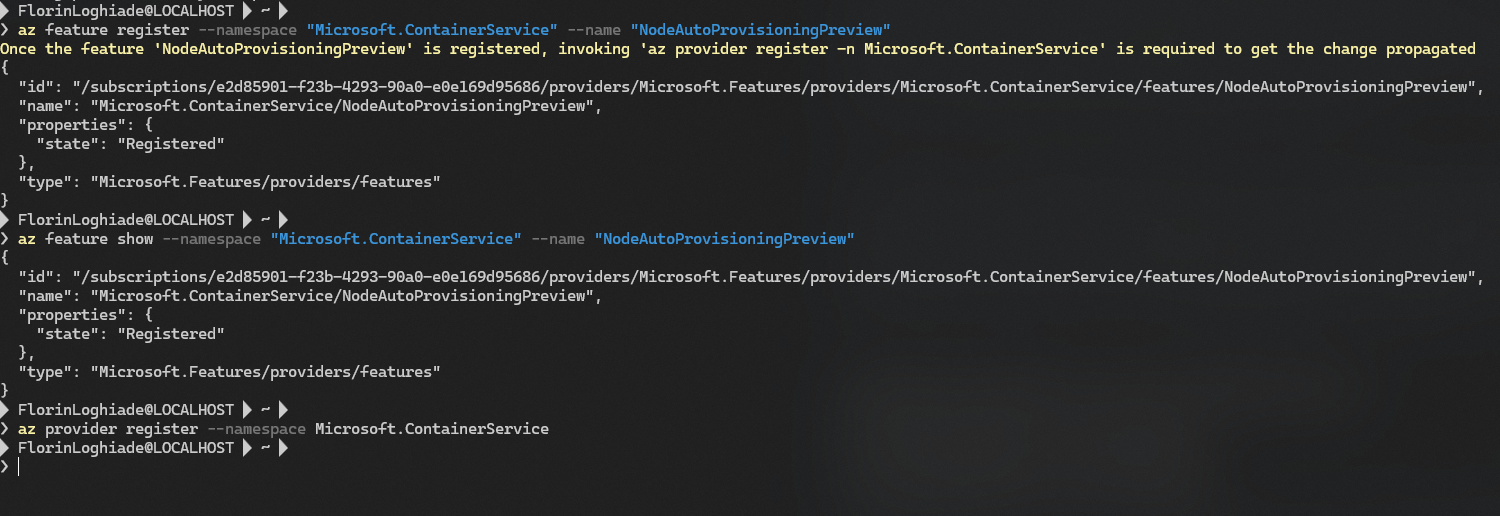
#Registration of the NodeAutoProvisioningPreview feature flag:
az feature register --namespace "Microsoft.ContainerService" --name "NodeAutoProvisioningPreview"
az feature show --namespace "Microsoft.ContainerService" --name "NodeAutoProvisioningPreview"
az provider register --namespace Microsoft.ContainerService
The feature registration process typically takes several minutes to complete, and you can check its status using the az feature show command.
Enabling NAP on New Clusters
Creating a new AKS cluster with NAP enabled is straightforward. The key parameter is --node-provisioning-mode Auto, which activates Node Auto Provisioning. Additionally, you must use Azure CNI networking in overlay mode with the Cilium data plane, as these are required network configurations for NAP to function properly.
$RESOURCE_GROUP_NAME=""
$CLUSTER_NAME=""
az aks create \
--name $CLUSTER_NAME \
--resource-group $RESOURCE_GROUP_NAME \
--node-provisioning-mode Auto \
--network-plugin azure \
--network-plugin-mode overlay \
--network-dataplane cilium \
--generate-ssh-keys
Configuring NAP on Existing Clusters
One of the significant improvements to NAP is enabling it on existing clusters, which was previously impossible. However, the network configuration requirements remain strict—only Azure Overlay with Cilium data plane is supported9. To enable NAP on an existing cluster:
$RESOURCE_GROUP_NAME=""
$CLUSTER_NAME=""
az aks update \
--name $CLUSTER_NAME \
--resource-group $RESOURCE_GROUP_NAME \
--node-provisioning-mode Auto \
--network-plugin azure \
--network-plugin-mode overlay \
--network-dataplane cilium
Advanced Configuration Options
NAP provides numerous customization options through Kubernetes custom resources, allowing you to fine-tune the behavior according to your specific requirements.
Example of nodepool configuration:
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
disruption:
consolidationPolicy: WhenUnderutilized
expireAfter: Never
template:
spec:
nodeClassRef:
name: default
# Requirements that constrain the parameters of provisioned nodes.
# These requirements are combined with pod.spec.affinity.nodeAffinity rules.
# Operators { In, NotIn, Exists, DoesNotExist, Gt, and Lt } are supported.
# https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#operators
requirements:
- key: kubernetes.io/arch
operator: In
values:
- amd64
- key: kubernetes.io/os
operator: In
values:
- linux
- key: karpenter.sh/capacity-type
operator: In
values:
- on-demand
- key: karpenter.azure.com/sku-family
operator: In
values:
- D
NodePool resources support a wide range of selectors that give you granular control over the types of nodes NAP can provision. Some of the available selectors include:
A powerful feature of NAP is its ability to consolidate workloads for better efficiency. This is controlled through disruption rules that determine when and how NAP should scale down node pools. These rules can be added to the NodePool definition:
disruption:
# Describes which types of Nodes NAP should consider for consolidation
consolidationPolicy: WhenUnderutilized | WhenEmpty
# 'WhenUnderutilized', NAP will consider all nodes for consolidation and attempt to remove or replace Nodes when it discovers that the Node is underutilized and could be changed to reduce cost
# `WhenEmpty`, NAP will only consider nodes for consolidation that contain no workload pods
# The amount of time NAP should wait after discovering a consolidation decision
# This value can currently only be set when the consolidationPolicy is 'WhenEmpty'
# You can choose to disable consolidation entirely by setting the string value 'Never'
consolidateAfter: 30s
The consolidation policy can be set to either:
WhenUnderutilized: NAP considers all nodes for consolidation and attempts to remove or replace underutilized nodes to reduce cost
WhenEmpty: NAP only considers nodes for consolidation when they contain no workload pods
This consolidation capability is particularly valuable for cost optimization, as it ensures resources are efficiently utilized and can even scale to zero when appropriate. When a traffic surge occurs, NAP can quickly detect the increased load and provision the correct number and type of nodes to handle it. Once the spike subsides, it efficiently cleans up unnecessary resources.
Resource Optimization and Cost Savings
NAP's ability to provision the correct VM sizes based on workload requirements leads to better resource utilization and cost optimization. Rather than over-provisioning resources based on anticipated needs, you can let NAP dynamically adjust infrastructure to match actual requirements.
The consolidation capabilities further enhance cost savings by automatically identifying opportunities to bin-pack workloads onto fewer nodes or to scale down entirely when resources aren't needed. This can significantly reduce cloud spending, particularly for non-production environments or workloads with variable resource needs.
Administrative Overhead Reduction
The most underappreciated benefit of NAP is the reduction in administrative overhead. With traditional node pool management, operators spend considerable time designing node pools, testing different VM sizes, and tweaking autoscaling parameters. I don't want to calculate how much time it took me to find the right size for an over 100 cluster deployment with different applications. I was dreaming of this website during the night.
With NAP, this hurdle is eliminated by automatically managing infrastructure decisions.
Limitations and Considerations
Despite its significant benefits, NAP currently has several limitations that should be considered:
Technical Limitations
OS Support: The current preview version does not support Windows and Azure Linux node pools. NAP can only manage standard Linux nodes.
Kubelet Configuration: NAP doesn't support kubelet parameters typically configured via node pool configurations. If you require custom kubelet configurations, alternative approaches are needed.
Network Requirements: NAP only works with Azure CNI in overlay mode with the Cilium data plane, which might require network configuration changes for existing clusters.
Monitoring and Debugging Challenges
Debugging can be more challenging with NAP than with traditional node pools. Since nodes are dynamically created based on workload requirements, it can be harder to predict which VM sizes will be used in advance. This requires adjustments to monitoring and troubleshooting approaches.
How I would classify it mostly but not as a rule of thumb:
Aspect
Traditional Node Pools
NAP Environment
Monitoring Focus
Node health
Workload patterns
Alert Thresholds
Static (CPU > 80%)
Dynamic (Deviation from mean)
Cost Tracking
Per-node
Per-workload
Capacity Planning
VM size forecasts
Trend analysis
Troubleshooting
Node-specific metrics
Workload scheduling lifecycle
Log Retention
Node-persistent
Centralized streaming
Cost Management
Effective monitoring becomes even more critical with NAP's dynamic provisioning approach:
Use Azure Monitor and Container Insights to track node utilization and scaling activities.
Implement cost management tools and budget alerts to monitor spending as NAP provisions resources.
Analyze scaling patterns over time to identify opportunities for optimization through custom NodePool configurations.
Comparison with Traditional Autoscaling Methods
Architectural Differences
The architectural difference between NAP and traditional Cluster Autoscaler lies in how they approach node management:
Cluster Autoscaler: This tool works with predefined node pools. Administrators must create and maintain separate node pools for different workload types with specific VM sizes. It scales these existing node pools based on pending pods.
Node Autoprovisioning: This doesn't require predefined node pools. It dynamically provisions nodes based on the exact requirements of pending pods, creating the optimal VM configuration on demand.
This architectural difference leads to significant divergence in how these two approaches handle diverse workloads. With Cluster Autoscaler, you might need multiple node pools to accommodate different workload types (CPU-intensive, memory-intensive, GPU-accelerated, etc.). NAP eliminates this complexity by determining the right VM type based on pod requirements.
NAP is a great step forward in Kubernetes infrastructure management, aligning with the cloud-native idea of automated, scalable infrastructure: "Treat your infrastructure as cattle, not as pets." By dynamically provisioning the resources needed by workloads without manual intervention or pre-planning, you can focus more on application development and less on infrastructure management.
With it installed on your clusters, you eliminate the need to adapt to workload requirements. When you migrate or start using NAP, you can expect faster scaling, better resource optimization, and a simplified management experience that allows you to focus more on your applications and less on infrastructure concerns.
I, for one, cannot wait for this feature to come out of the preview so I can migrate my cluster to it :)
Node image retirement is not an emergency if you treat it as a predictable operating model. How to migrate images without chaos, what to test, and how to govern the decision.
APIM isn't just a gateway. It's a governance layer that enforces consistency across AKS, Container Apps, and other platforms. When to use it and when to keep things simple.
Network policy is not theoretical; Cilium and eBPF make it practical. Learn when segmentation actually matters, how to observe before you enforce, and why most teams get it wrong at first.












{kind=link}