KEDA works excellent when paired with code that runs on top of the Azure Functions containers. You have running services that monitor a queue, topic, storage, and so on, which scale up and down depending on specific metrics.
While this is a prime candidate to demo for KEDA, it can also create scaled jobs based on those metrics. For example, a deployment that doesn't need to run 24/7 but only runs when a specific event happens. Say a Service Bus message got dead lettered and was forwarded to a particular queue for processing. You can configure KEDA to spin a job to process that message and use those resources for just that time.
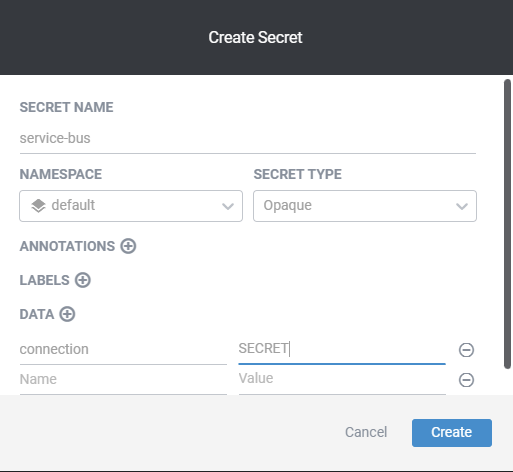
One problem with the KEDA documentation regarding Scalable Jobs is that it's not that clear when setting up the secret for the message queue or other systems and how to set up a trigger.
The main idea is that you set up a Kubernetes Secret with a K/V Pair with the connection and secret. Then in the KEDA spec, you need to add a TriggerAuthentication and then set up the ScaledJob, which references the trigger mentioned above at the end.
In the example below, we have a service bus endpoint configured as a Kubernetes Secret, referenced in the Trigger Authentication and consumed by the Scaled Job, which starts a job every time a message lands in the test queue.
The spawned container doesn't consume the message from the queue, and as you can assume from the parameters configured on the ScaledJob, it will pop jobs as long as there's a message inside the queue.
To avoid that type of problem, you need to consume the message from the queue that spawned the job in the first place.
The spawned container doesn't consume the message from the queue, and as you can assume from the parameters configured on the ScaledJob, it will pop jobs as long as there's a message inside the queue.
To avoid that type of problem, you need to consume the message from the queue that spawned the job in the first place.
How do I use it?
I'm using the scaled job feature of KEDA to process dead-lettered messages, send notifications, and other processes.
Most of my systems are based on the pub/sub architecture, and when the rare event of a dead letter happens, I need a way to reprocess the message or send out alerts. In other cases, notification systems should only run when a notification has to be sent, so e-mails, Teams messages, and other types of notifications are only sent when a message appears in a queue.
There are also other ways of using it where I'm going to spawn a job to process a long-running job (5 hours or more). It's pretty resource intensive, which instructs the cluster auto-scaler for the AKS cluster to add a new node to prevent evictions if other systems start consuming resources simultaneously. If that job would be a deployment, it would consume resources for nothing and have an extra node for no additional benefit and pay the cost for it.
Event-driven workloads demand different compute models; Container Apps Jobs scales to zero and costs pennies, while AKS provides control and state coordination at the expense of operational burden. This guide shows you how to choose correctly based on your actual workload, not your last successfu...











{kind=link}